みなさんこんにちは武田です。
少し暖かい日が多くなってきました。

流れている感じが弱い巻雲の写真が撮れました。
巻雲にもいろいろあって、流れてスジを引いているような雲ではなくて、もつれた紐のようになったりします。
どういう条件でそうなるのでしょうね。
スジ雲が流れていくように見えるのは、上空の速度差のせい、という事なので、逆に速度差が少ないとこうなるのでしょうか。
実際の雲のパターンは細かくて繊細です。なかなかこうは再現するのは難しそうです。
さて、前回は粒子のシミュレーションで作った流れるようなすじ雲を、Point Density を使って Cycles で点の密度から雲を表示してみました。
ひとすじの雲は、そう悪くない表示はできたのですが…

半透明が絡んでいることもあって、すじ雲をいっぱい並べようとすると、レンダリングがとても重くなってしました。
できれば、レンダリングの速い Eevee を使って表示したいところです。
もくもくとした積雲を表現するときに、Cycles と Eevee のボリュームの表示の特徴を調べてみましたが、雲の塊の中に光が入り込んで、多重散乱することが重要な場合には Eevee の表現力では無理がありました。
今回の様に、あまり濃くない雲なら、多重散乱は重要ではないですから、Eeveeでも充分な表現力がありそうです。
ところが、Point Density の機能を使って、粒子が濃く集まっている場所を濃く、粒子が疎な場所を薄く…という表示をするための機能が(現時点での) Eevee にはまだありません。
仕方がないので、Eeveeで利用することができるボリュームデータを作ってみます。
(ということで、今回は blender だけで実現できる内容ではないのです…残念ですが、機能が無いので仕方がない…!)
さて、粒子シミュレーションのままだと情報が抜き出せないので、粒子の位置に頂点があるメッシュデータにしておきます。
原点に頂点が1つだけあるオブジェクトを作成して、Particle Instance モディファイアを使います。
本来は、任意のオブジェクトを、パーティクルシミュレーションを使ってコピーするための物ですが、今回は頂点1個だけを複製するわけです。
(前々回にEeveeで粒子の雲を表示するためにも使いました)
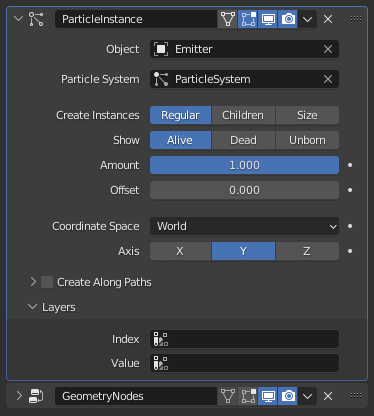
これを適用してやれば、シミュレーションのデータから頂点の集合体が作成できます。

頂点のデータは、bleder 上で python を使って見ることができます。
試しにpython コンソールから0番目の粒子の位置を見てみましょう。
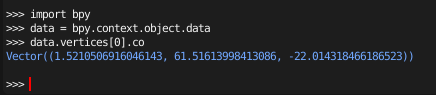
現在アクティブなオブジェクト(bpy.context.object)の、
メッシュデータ(.data)の、
頂点データ(.vertices[…])の座標(co)
というような形でデータが収容されています。
これさえ分かってしまえば、pythonを使ってこのデータをファイルに出力して、
blender意外で何か粒子データが扱えるツールを使ってボリュームデータに変換をしてやる、ということができるわけです。
ここから先のやり方は幾つも考えられるわけですが…
今回は、たまたま、別件で Blender用のボリュームデータ用のフォーマット(Open VDB) のファイルを作成することをしていたので、それを利用しました。
公式のページを見ながら、必要なライブラリなどを頑張って導入して、自分で作ったxyz座標のボリュームデータから、.vdb のファイルを作成するちょっとしたプログラムを組んでいたのです。
ということで、それを使って .vdb ファイルにします。
粒子の分布から、ボリュームの濃い薄いのデータに変換の仕方は、次のような考えで行いました。
粒子が密集して濃い場所にいる粒子は、小さくて濃い、コンパクトな雲の塊がある。
粒子がまばらで薄い場所にいる粒子は、薄くて大きく広がった雲の塊がある。
と解釈して、これを全て重ね合わせたものがボリュームの濃度であるとします。

この考えでの変換の模式図です。
粒子の大きさを可変にしないで、一定の大きさとして解釈してしまうと、まばらなところでは何もない隙間の空間ができてしまいます。
逆に、そうならないように粒子を大きくすると、濃く粒子が集まったところでは折角の解像度がなまってしまいます。
ということで、密集度合いに応じてサイズが変わるものとして考えて、重ね合わせます。
ただ、粒子の濃い薄いを自力のプログラムで計算するので、少々手間がかかります。
粒子がどれぐらい密集しているのか、という情報をあらかじめ計算してファイルに一緒に保存しておけば、後から自分で粒子の密集度合いを計算しないで済むので、プログラムを組むのが随分楽になります。
この「どれだけ密集しているのか」の計算をするのに便利なpythonのライブラリが、もとからblenderに組み込まれているので、折角なのでそれを使ってみます。
使うのは、KDツリーという機能で、近傍にある頂点の検索などができる機能です。
ある粒子の周りの濃い薄いの情報を調べるには、遠くの粒子のデータは必要なく、近くの粒子のデータだけあれば充分です。
近傍検索ができれば、総当たりで粒子を調べる必要が無くなって、(劇的に)高速化ができます。

mathutils の中にある機能なので、importをしておきます。
まずはデータにある粒子数(頂点数)の確認しておきます。
138605、大体13万粒子ぐらいですね。
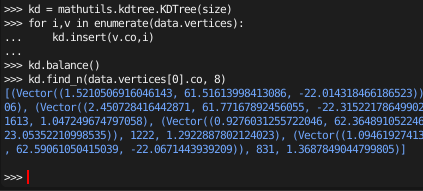
kdtree ライブラリの中の KDTree という構造を作ります(kdという名前にしました)。
最初に、約13万粒子のデータだぞ、とデータ数の初期値を与えておきます。
次いで、ループ文を使って、kd に粒子の位置データを送り込みます。
kd.balance()を実行すると、近接する粒子を効率よく検索するためのツリー構造が構築されます。
あとは、find_n(位置、個数) を実行すると、ある場所の近くの粒子のデータを得ることができます。
ここでは、粒子 0 の近くの 8 粒子の位置や距離が得られています。
(自分自身が必ず距離0で存在するので、7つというべきでしょうか…)
こうして得られる近傍粒子までの距離の平均でも記憶しておけば、密集しているかバラバラの疎な場所にいる粒子なのかが分かります。
ということで、近傍粒子との距離情報も含めた、粒子データのファイルを出力して、自作のプログラムで .vdb ファイルに変換をしてみました。
(実際には上の図のようにコンソール上で手入力…ではなくて、手順をスクリプト化しています。もちろん!)
.vdb ファイルが作成できました。
Eevee で読み込んで、濃度などを適度に調整をします。

うまくいったようです。薄くなった部分が、きちんと薄く広がっています。
単に粒子をそのままボリューム化すると、薄いところが粒粒になってしまう弱点は解消されました。

試しに並べてみても、それほど重くなりません。この程度の質であれば、マウスでつまんで普通に動かせます。

ということで、複数種類パターンを作っておいてたくさん並べてみます。

ちょっとわざとらしい分布である気もしますが、自然な分布の仕方するように頑張ればもっといい感じが出そうになってきました。
これぐらいの数の雲を配置して、パターンを乱す為に、大きくて薄い数個の雲を手で配置する、という事をしています。

Cyclesの時にはこんなにボリュームを置くとちょっと速度的に無理だったのですが、普通に数秒から10秒程度でレンダリングができました。
(繰り返しですが、多重散乱が必要ないような薄い雲の分布だからEeveeでも大丈夫、ということなのですが)
どうやらこれですじ雲のような雲が広がる空は表現できそうです。
ということで、一区切りできたところで、続きます。
